

Nyhetsartikler og råd som ikke er skrevet av mennesker
Barn og unge får stadig noe nytt å forholde seg til digitalt. Hva er sant? Hva er juks? Og hva er skrevet av kunstig intelligens eller enklere dataprogrammer?

Noen råd du kan gi barn og unge om robotartikler
- Vær klar over at det finnes tekster som ikke er skrevet av mennesker, men av dataprogrammer. Det gjelder alt fra nyhetsartikler til eventyr eller produktinformasjon.
- Noen robotartikler kan inneholde mange korrekte opplysninger, men likevel være misvisende (se eksempler nedenfor).
- La det bli en vane å sjekke «byline», altså å sjekke navnet og tittelen til den som har skrevet teksten, det er alltid nyttig å vite hvem som er avsender. Noen ganger står det at teksten er skrevet av et dataprogram. Andre ganger varsles man ikke, og da er det vanskelig å oppdage om det er et dataprogram som er forfatter.
- Dataprogrammer kan ha noe som kalles «kunstig intelligens» som kan beregne ting som mennesker ikke klarer å regne ut, det kan være veldig nyttig. Men kunstig intelligens kan også være rasistisk eller komme med fæle råd.
- Siden tekster fra kunstig intelligens kan inneholde dårlige synspunkter, bør du etterprøve med en god menneskelig kilde. Men husk også at menneskelige kilder kan gi dårlige råd eller komme med faktafeil og fæle holdninger, så det gjelder å finne gode kilder.
(Bildet øverst: Shutterstock / Phonlamai Photo.)
Ikke alle robotartikler er laget av kunstig intelligens
Enkle robotartikler lages automatisk ved at man har et dataprogram som henter opplysninger fra bestemte kilder og plasserer disse opplysningene inn i setninger som ligger klare. Man kan ha et dataprogram som for eksempel overvåker en værtjeneste, og så ordner programmet resten. Et tenkt eksempel:
Setningen ser slik ut før opplysningene lastes automatisk ned:
«Det blir ___ på ___ ___ i ___.»
Hver ledige plass skal fylles med bestemte data:
«Det blir (type vær) på (ukedag) (når på døgnet) i (område).»
Dette blir til: «Det blir sol på tirsdag ettermiddag i Kristiansand.»
Slike programmer kan også overvåke automatiske tjenester som sjelden kommer med data. I løpet av minutter, før noen journalist har rukket å sette seg foran tastaturet, kan dataprogrammet ha publisert en artikkel om for eksempel et jordskjelv.
Dataprogrammer kan også hente inn opplysninger fra fotballkamper, hvis noen mennesker først har tastet inn fakta om hvem som scoret mål, hvem som ble utvist, hva dommeren het og så videre. Dette kan for eksempel kombineres med fakta fra værmeldingen:
«Det sto 1-1 mellom Lillestrøm og Brann etter første omgang. Kampen ble spilt i strålende sol. Ingen ble utvist i første omgang.»
Samtidig kan det ha vært opptøyer på tribunen uten at dataprogrammet har fått det med seg. Folk kan ha stormet banen og noen kan ha blitt sendt til sykehus før politiet fikk ryddet opp og kampen kunne fortsette. Robotartikkelens program tar ikke høyde for slikt, dermed kan artikkelen om kampen gi et falskt virkelighetsbilde.
I en fotballkamp kan det også overraskende komme flere lokale regnbyger uten at værmeldingen hadde data om det. Eller kanskje dommeren ble byttet ut på grunn av sykdom. En journalist ville ha oppdaget både regnskurene, opptøyene og dommerbyttet.
En redaksjon har ikke har råd til å sende en journalist til samtlige begivenheter som finnes i verden. En fordel med robotartikler er at det kan produseres mange flere artikler og slik kan hver og en av oss lettere finne opplysninger som vi er ute etter.
En annen fordel er at noen synes kanskje det er lettere å lese setninger enn tabeller.
Å plassere fakta inn i ledige plasser i setninger som ligger klare, er en enkel form for automatisk produksjon av tekster. For eksempel mediekonsernet Amedia samler inn opplysninger om handel med boliger og lar et program lage enkle artikler om dette. Det står hvem som kjøpte, hvem som solgte, hva prisen ble og hva adressen er. I tillegg vises et bilde av boligområdet, tatt fra fly. Og man kan klikke på et kart for å se den nøyaktige plasseringen.
Akkurat hvem som kjøpte og solgte en bolig, er det kanskje ikke så stor nytte av å lese om i avisen. Men det kan være nyttig å følge med på boligprisene.
Bildet under viser hvordan en slik artikkel vises i Amedia-avisene:

Leseren har ganske sikkert lagt igjen sin egen adresse ved bestilling av abonnement, slik kan avisen vise persontilpassede nyheter med boliger som er solgt i nabolaget til leseren. I overskriften er det derfor adressen som avisen løfter frem. Meldingen er egentlig: «Hei, sjekk hva som foregår i nabolaget ditt!»
Det er mulig teknikken ikke sitter helt ennå, for konsernet spør leserne om hvor godt den enkelte robotartikkel traff geografisk:
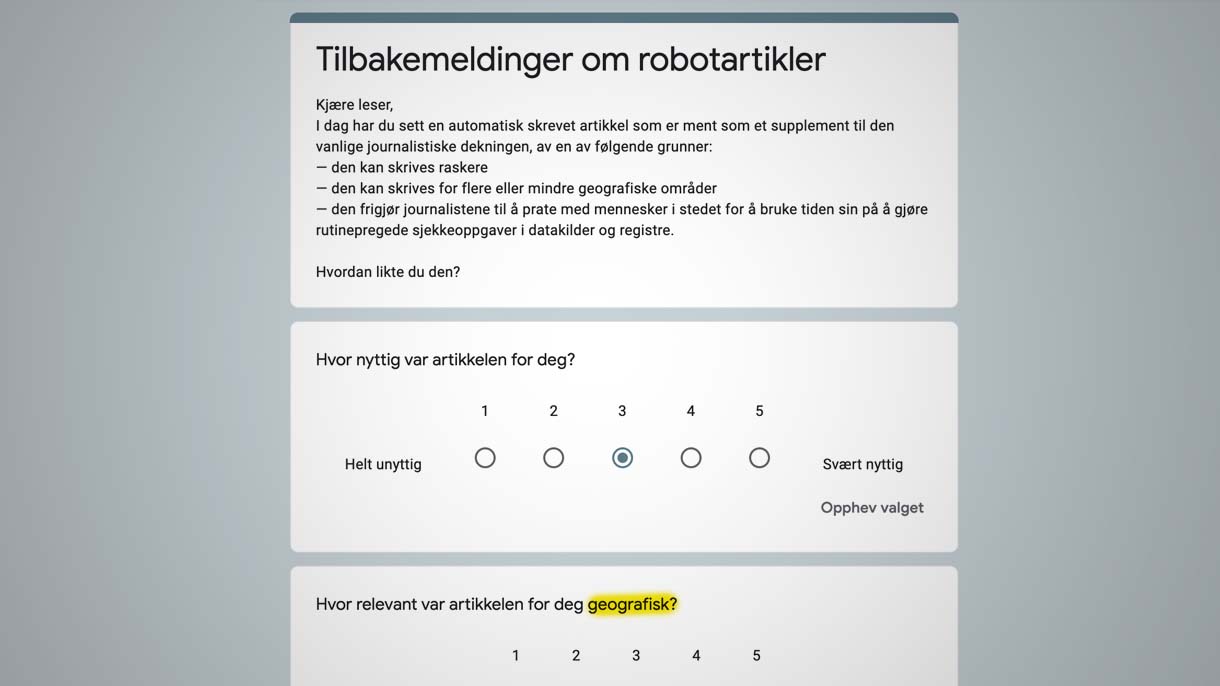
Det er altså ikke bare innen markedsføring eller sosiale medier man driver med persontilpassede visninger, det foregår også innen nyhetsformidling.
En fordel med persontilpassede nyheter er at du får vite mer om akkurat det du er interessert i, for eksempel om hva som foregår i ditt eget nabolag eller hvordan det går med fotballaget du heier på. Ulempen er at du får et smalere nyhetsbilde, du blir mindre opplyst om resten av Norge og resten av verden.
Kunstig intelligens skriver artikler
Robotartikler om været eller resultatene fra fotballkamper er ganske enkle med «copy and paste». Noe mer avansert er programmer som stjeler setninger fra for eksempel Wikipedia og stokker om på ordene slik at det ser ut som setningene ikke er kopiert. Her er et eksempel.
Man kan også få artikler som et dataprogram har skrevet fra bunnen av, det er kanskje først da man virkelig snakker om kunstig intelligens. Se dette eksempelet fra dataprogrammet GPT-3. I eksempelet ga noen journalister programmet beskjed om å skrive en artikkel som skulle si at vi mennesker ikke har noe å frykte fra kunstig intelligens. Man skriver altså en bestilling til programmet angående tema og oppgave, og så fikser programmet resten.
Journalister la inn noen få setninger som de ville skulle tas med, men resten av artikkelen ble skrevet av programmet. GPT-3 lagde mange ulike utkast som redaksjonen kunne ha publisert. Men redaksjonen valgte å sy sammen avsnitt fra ulike utkast for å vise mer variasjon.
Dataprogram ble rasist
Teksten i eksempelet over stammer altså i hovedsak fra dataprogrammet GPT-3 som visstnok har milliarder av parametere for selvlæring. Men slik selvlæring kan også gå galt av sted. I denne lenken (et stykke ned i artikkelen) ser du eksempler på at kunstig intelligens kan ende opp med rasistiske tekster.
Programmer innen kunstig intelligens kan sendes ut på internett for å lære seg selv opp ved å lese tusener på tusener av nettsider. Men på internett er det både troll, vitser, ironi, løgn, faktafeil og folk med fæle holdninger. Den kunstige intelligensen forstår ikke nødvendigvis sammenhengen utsagnene står i. En ungdom kan for eksempel skrive om et dataspill at det er gøy å drepe. Det betyr ikke at ungdommen mener at det er gøy å drepe i virkeligheten. Men den kunstige intelligensen kan etterpå finne på å bruke utsagnet «det er gøy å drepe» på helt feil måte i en tekst som den produserer.
Filmklippet nedenfor viser en samtale mellom et menneske og dataprogrammet GPT-3. Samtalen foregikk i tekstform, men en mann ville gjerne tydeliggjøre det hele ved å filme seg selv som henholdsvis menneske og maskin og så fremføre samtalen muntlig. Kunstig intelligens vil i fremtiden antagelig bli svært mye bedre, fordi man forhåpentligvis vil makte å mate programmene med etiske regler, og man vil også drive store mengder med etterarbeid med manuell finjustering. Men det er samtidig skremmende hva en maskin kan finne på si i dag.
Bør være åpenhet om kildene til kunstig intelligens
I denne lenken kan du se ulike programmer innen kunstig intelligens og hvilke nettsteder de leser for å bedrive selvlæring. Se for eksempel denne sammenligningen mellom to slike programmer. Figuren viser at omkring 3 prosent av selvlæringen foregår ved å lese Wikipedia (som inneholder 6 millioner artikler på engelsk). Oversikten antyder også at det er kun engelske tekster som er kilde. Det kan kanskje bety at hvis kunstig intelligens skal skrive noe om Norge, er ingen opplysninger hentet fra norske tekster.
Kina har laget «Wudao 2.0» som visstnok skal være mer omfattende enn GPT-3 som kommer fra USA, samtidig viser denne figuren at det er noe vanskeligere å få ut informasjon om hvor på nettet Wudao driver selvlæring. Verdens helseorganisasjon (WHO) mener at det bør være åpenhet om hvor programmene med kunstig intelligens bedriver selvlæring. Hvilke bøker, nettsider og sosiale medier leser slike programmer? Og hvordan ser programkodene ut som mennesker har lagt inn? Her kan du laste ned hva WHO mener om helse og kunstig intelligens.
GPT-3 drives av selskapet OpenAI som har som mål at kunstig intelligens skal være trygg og til hjelp for mennesker. Selskapet er grunnlagt av blant annet Elon Musk.
Leter etter mønstre og sammenhenger
Vanligvis går dataprogrammer ut på at mennesker skriver koder som dataprogrammet må følge. På et vis har da mennesker full kontroll på alt. Men ved kunstig intelligens lærer programmet seg selv opp til å finne mønstre i tekstene eller bildene som undersøkes. Dermed kan programmet finne sammenhenger som mennesker ikke makter å finne. Slik kan et program for eksempel gi varsel om mulige svindlere, fordi programmet selv har funnet ørsmå tegn i språket som øker sannsynligheten for at det er en svindler som står bak en henvendelse.
Ved at programmet undersøker millioner av setninger, kan programmet også selv forfatte setninger basert på beregninger om hva som bør bli det neste ordet i en setning som ikke er ferdig skrevet. Selvlæringen går for eksempel ut på hvilke ord som pleier på dukke opp i nærheten av hverandre. Ved ordet boligbrann pleier ordet politi å stå ikke så langt unna. Et visst slektskap er det altså mellom de to ordene.
Slik selvlæring er mye mer avansert enn når et program bare skal lempe inn enkeltopplysninger slik Amedia-artiklene gjør.
Men å lempe inn enkeltopplysninger i koder som mennesker har laget, betyr at mennesker har god kontroll på hvordan programmet skal oppføre seg. Ved kunstig intelligens er det risiko for at programmet kan skrive noe hårreisende som mennesker ikke kunne forutse.
Får menneskelig navn og utseende
Det er selvsagt masse fint med kunstig intelligens, men man må dessverre være forberedt på at kunstig intelligens også mates med synspunkter fra netttroll, politikk og alt mulig annet fra nettet, før programmet selv begynner å skrive artikler, eventyr, nyheter og dikt – eller gir helseråd eller svarer på spørsmål om meningen med livet.
Det er derfor viktig at leseren gjøres oppmerksom på om teksten stammer fra et menneske eller kunstig intelligens. Men de som formidler kunstig intelligens, synes det er er artig å gjøre programmet så menneskelig som mulig, og gir gjerne den digitale roboten et menneskelig ansikt og navn, dermed er det vanskeligere for leseren å oppdage hvem eller hva som er avsender.
I denne lenken kan du se at kunstig intelligens har fått et ansikt og muntlig tale.
Se en robothilsen fra Barnevakten her. Vi lagde filmen gratis mot å legge igjen navn og e-postadresse for å motta reklame fra selskapet Synthesia som står bak teknikken.
For ordens skyld: Hovedbildet til denne artikkelen viser fysiske roboter som skriver på et tastatur. Det er en unødvendig omvei, bildet brukes bare fordi det ser artig ut. Med robot i denne artikkelen, mener vi dataprogrammer.
Les også
Bestill foredrag

{kind=link}
{kind=link}